Here is a summary of my learning from watching season 3 of Destroy All Software screencasts.
Which kind of code should go into Models?
Gary is fond of an architecture style for web applications, which is equivalent to the so-called clean architecture described by Brandon Rhodes here:
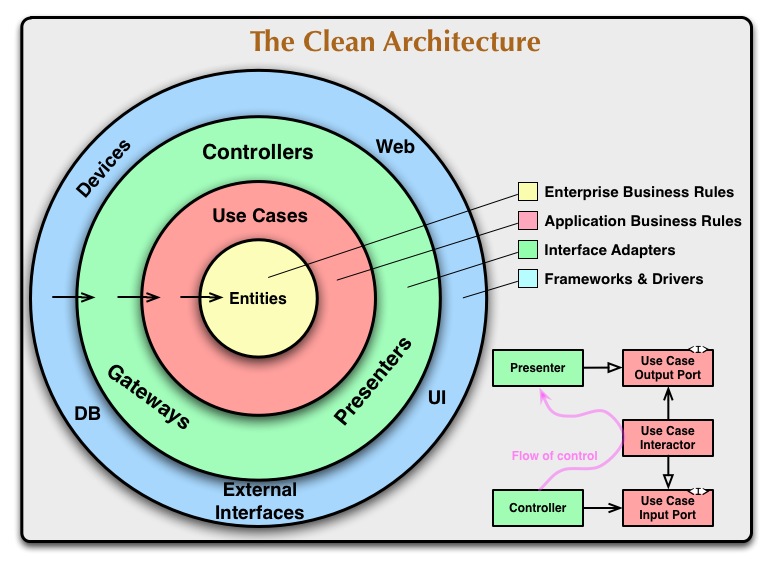
Following this architecture, the code inside model classes (in Rails, this would be Active Record classes) should be either:
- validations/relationships
- mutation (set & save)
- wrapper (meaningful getter)
- queries (where/order/etc <- best to always be only there)
- creation (create and save)
And that’s it.
Things with more application logic (aka business rules) should go into their own libraries, decoupled from the framework or ORM. This leaves the models with no extra dependencies apart from the ORM, and make the code implementing the application logic easier to test and modify.
I like this idea very much, but it seems often quite hard to put it in practice, because most web frameworks encourage coupling with its APIs. I'm yet to see a framework that really encourages this kind of separation of concerns. Even the so-called micro-frameworks often fall in this trap.
My feeling is that you need extra discipline to use this architecture. I think there is a complexity threshold for deciding when the effort will pay off.
Outside-in TDD
I already mentioned outside-in TDD in the summary for the second season, when Gary talked about spiking.
Here he shows two approaches to do it:
-
stubbing dependencies: here you program by wishful thinking, and design the dependencies by stubbing them out (i.e. using mocks to define the interaction with the code not yet implemented).
-
stash (using Git): implement a feature, but instead of stubbing a wished feature, stash the current code (i.e. set apart the current code via git stash), test and implement the wished feature TDD-style, commit it, unstash the previous code (git stash pop), finish implementing test with the newly developped code and then commit it.
Both approaches are valid and result in equivalent granularities, but the order of commits will be different (with stubbing, the order will be more like top-down) and tests with the stub approach tend to be more isolated.
Testing code that calls HTTP APIs
Here is a cool idea: consider external HTTP APIs like “databases”, and test your wrapper code mocking the HTTP interactions with a tool to replay interactions like you would test with a fake database.
There is a neat tool for doing this called vcr which is written in Ruby, there is a Python port called vcrpy.
What this VCR tool does is: it records HTTP requests into a "cassette" (an YAML file) to replay the requests later from it when running the tests and then checks if the requests match the expected ones from the cassete file.
This makes the tests verify at the boundary of your app with the external HTTP API, which is arguably more reliable than verifying interactions with proxy objects (see this talk for about this idea of boundaries.)
Here is the introduction for vcrpy:
VCR.py simplifies and speeds up tests that make HTTP requests. The first time you run code that is inside a VCR.py context manager or decorated function, VCR.py records all HTTP interactions that take place through the libraries it supports and serializes and writes them to a flat file (in yaml format by default). This flat file is called a cassette. When the relevant piece of code is executed again, VCR.py will read the serialized requests and responses from the aforementioned cassette file, and intercept any HTTP requests that it recognizes from the original test run and return the responses that corresponded to those requests.
I've recently started using vcrpy, and I like the approach.
However, I'm not sure about
One possible drawback of this approach is that the library must support the HTTP library you're using, to be able to intercept the requests -- VCR.py currently lacks support for Twisted Web Client.
Dealing with untested Code
In a series of episodes, Gary demonstrates how to tackle an untested method, adding tests and then refactoring it, keeping the test suite updated.
In this case, you can’t isolate upfront. Sometimes you can start with "smoke tests" (e.g. simple output test of a happy path).
Gary’s example is a Rails controller method, he starts by writing RSpec contexts (just the names/descriptions of the tests), one for every code path (namely, two for every conditional), then sort them from the happiest path to the "saddest" path.
Having that, then he starts writing tests in that order, always checking the tests fail for every context when appropriate -- this way ensuring that the test is verifying the right thing.
I found this quite useful, since I often find myself having to deal with untested code -- often it's my own (lazy programmer detected!).
Aside about testing tools for Python
These videos got me envious of Ruby programmers because of RSpec, it’s a really powerful tool. I couldn't find any good equivalent for Python yet.
- If you just want a nice output you may try out spec (or pinochio), that work with nosetests
- pytest-describe almost cuts it, but it only supports one level of nesting and its reporting is quite ugly due to limitations of the implementation.
- mamba looks promising -- I like the API, but it's currently lacking documentation.
- I've recently found out about pyvows which looks really cool. I really like the API, but I'm not sold on requiring gevent for my test suite.
I even toyed around with a class decorator allowing for a similar API but relying only on unittest which seems to work well with nose and pytest, but I don't know if it's worth the hassle (let me know if you think this is useful).
Python doesn't make it easy to build this kind of tool, I'm really envious. =)
Emacs, chainsaw of chainsaws
Emacs is written in Elisp, and can be extended with Elisp -- this offers a great level of customization. Also, Emacs environment knows about itself: for example, the help system is dynamic and can even show your own custom shortcut for a function. Vim doesn’t have anything like that, help system are static text files.
You can build vim inside Emacs, but you could never build Emacs inside vim.
However, a fresh Emacs installation (without customization) is less usable than a fresh Vim installation.
Better structure for Bash scripts by using many small functions.
This:
userinfo() {
grep "^$1:" /etc/passwd
}
extract_uid(){
cut -d: -f3
}
extract_home(){
cut -d: -f6
}
echo User ID: $(userinfo $1 | extract_uid)
echo Home: $(userinfo $1 | extract_home)
is better than this:
echo User ID: $(grep "^$1:" /etc/passwd | cut -d: -f3)
echo Home: $(grep "^$1:" /etc/passwd | cut -d: -f6)
Last one is shorter, but the former is easier to read and more composable.
TDD: when to generalize
Deciding when to generalize in TDD can be difficult, depending on your code and process.
In case you start your tests with the happy path (as opposed to starting with edge cases), here are some situations to help you decide when it's time to generalize instead of sliming (hardcoding values or writing fake implementation just for the current test to pass).
-
If there is a pending test (not yet implemented) that will force generalization, use that: implement the test and then generalize.
-
If sliming is harder than generalize, just generalize already.
-
If the implementation is obvious and easy (e.g., it's just calling code that's already tested and trusted), generalize, then consider the edge cases and write tests for them.
Note that this is illustrative, but not comprehensive -- there are probably.
TDD: bad expectations
Here are some notes about bad expectations/assertions in the test code, which are bad because they mine our confidence in the test suite.
Negative expectations (e.g., asserting that some function was NOT called, or that some expression isn't true) are dangerous because it's easy to miss a case where result can be incorrect and the assertion still pass.
The same is true for partial matches (checking containment or substring) like:
'connected' in status # what if status is "disconnected"?
Tests that obsess about implementation (like, a test checking the internal state of the component being tested) are also bad. This kind of test pours concrete over the code, making changes harder.
Finally, it’s best to write tests against the broad interface of a class, instead of tests for helper methods in it. In the end, the broad interface is what really matters, and the helper methods have higher probability to be changed later, best not to pour concrete around them either.
That's it for season 3 -- thanks for reading! :)