Update: This tutorial isn't up to date with the latest and greatest of Scrapy. You should follow the official documentation instead, I've worked together with other Scrapy developers to make it better. I'm leaving this article online for archival purposes only.
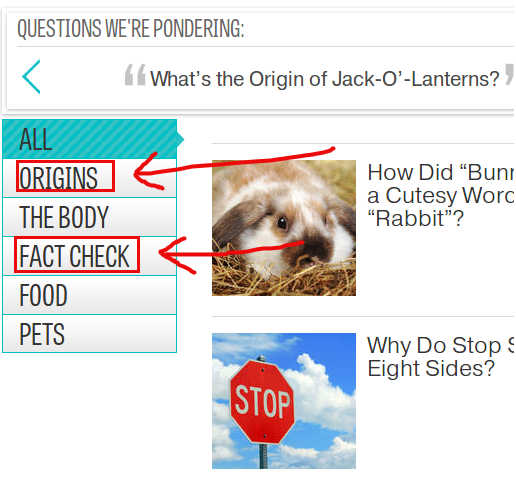
Imagine you want to extract content from the Web that isn't all in only one page: you need a way tonavigate through the site to get to the pages that contain the useful information. For example, maybe you want to get the latest "big questions" articles of the Mental Floss website, but only those in theOrigins andFact Check categories.
If you have an interest in Python and web scraping, you may have already played with the nice requests library to get content of pages from the Web. Maybe you have toyed around using BeautifulSoup or lxml to make the content extraction easier. Well, now we are going to show you how to use the Scrapy framework, which has all these functionalities and many more, so that solving the sort of problem we introduced above is a walk in the park.
It is worth noting that Scrapy tries not only to solve the content extraction (called scraping), but also the navigation to the relevant pages for the extraction (called crawling). To achieve that, a core concept in the framework is theSpider -- in practice, a Python object with a few special features, for which you write the code and the framework is responsible for triggering it.
Just so that you have an idea of what it looks like, come on take a peek at the code of a little program below that uses Scrapy to extract some information (link, title and number of views) from a YouTube channel. Don't worry about understanding this code yet, we're just showing it here so that you have a feeling of a code using Scrapy. By the end of this tutorial, you'll be able to understand and write programs like this one. =)
import scrapy
from scrapy.contrib.loader import ItemLoader
class YoutubeVideo(scrapy.Item):
link = scrapy.Field()
title = scrapy.Field()
views = scrapy.Field()
class YoutubeChannelLister(scrapy.Spider):
name = 'youtube-channel-lister'
youtube_channel = 'LongboardUK'
start_urls = ['https://www.youtube.com/user/%s/videos' % youtube_channel]
def parse(self, response):
for sel in response.css("ul#channels-browse-content-grid > li"):
loader = ItemLoader(YoutubeVideo(), selector=sel)
loader.add_xpath('link', './/h3/a/@href')
loader.add_xpath('title', './/h3/a/text()')
loader.add_xpath('views', ".//ul/li[1]/text()")
yield loader.load_item()
Before we talk more about Scrapy, make sure you have the latest version
installed using the command (depending on your environment, you may need to use
sudo or the --user option for pip install):
pip install --upgrade scrapy
Note: depending on your Python environment, the installation may be a bit tricky because of the dependency on Twisted. If you use Windows, check out the specific instructions in the official installation guide. If you use a Debian-based Linux distro, you may want to use the official Scrapy APT repository.
To be able to follow this tutorial, you'll need Scrapy version 0.24 or above. You can check your installed Scrapy version using the command:
python -c 'import scrapy; print scrapy.__version__'
The output of this command in the environment we used for this tutorial is like this:
$ python -c 'import scrapy; print scrapy.__version__'
0.24.2
The anatomy of a spider

A Scrapy spider is responsible for defining how to follow the links "navigating" through a website (that's the so-called crawling part) and how to extract the information from the pages into Python data structures.
To define a minimal spider, create a class extending scrapy.Spider and give it a name using thename attribute:
import scrapy
class MinimalSpider(scrapy.Spider):
"""The smallest Scrapy-Spider in the world!"""
name = 'minimal'
Put this in a file with the name minimal.py and run your spider to check if
everything is okay, using the command:
scrapy runspider minimal.py
If everything is fine, you'll see in the screen some messages from the log
marked as INFO and DEBUG. If there is any message marked as ERROR, it
means that there is something wrong and you need to check for errors in your
spider code.
The life of a spider starts with the generation of HTTP requests (Request
objects) to put
in motion the framework engine. The part of the spider responsible for this is
the start_requests() method, that returns an
iterable with the
first requests to be done for the spider.
Adding this element to our minimal spider, we have:
import scrapy
class MinimalSpider(scrapy.Spider):
"""The smallest Scrapy-Spider of the world, maybe"""
name='minimal'
def start_requests(self):
return [scrapy.Request(url)
for url in ['http://www.google.com', 'http://www.yahoo.com']]
The start_requests() method must return an
iterable of
scrapy.Request
objects, which represent an HTTP request to be made by the framework (these
contain data like URL, parameters, cookies, etc) and define a function to be
called when the request is complete -- a callback.
Note: if you are familiar with implementing AJAX in JavaScript, this way of work dispatching requests and registering callbacks may sound familiar.
In our example, we return a simple list of requests to Google and Yahoo
websites, but the start_requests() method could also be implemented as a Python
generator.
If you have tried to execute the example like it is now, you may noticed that there is something still missing, because Scrapy will show two messages marked as ERROR, complaining that a method was not implemented:
...
File
"/home/elias/.virtualenvs/scrapy/local/lib/python2.7/site-packages/scrapy/spider.py",
line 56, in parse
raise NotImplementedError
exceptions.NotImplementedError:
This happens because, as we didn't register a callback for the Request objects,
Scrapy tried to call the default callback, which is the parse() method of the
Spider object. Let's add this method to our minimal spider, so that we can
execute it:
import scrapy
class MinimalSpider(scrapy.Spider):
"""The 2nd smallest Scrapy-Spider of the world!"""
name = 'minimal'
def start_requests(self):
return (scrapy.Request(url)
for url in ['http://www.google.com', 'http://www.yahoo.com'])
def parse(self, response):
self.log('GETTING URL: %s'% response.url)
Now, when you execute it using the command:scrapy runspider minimal.py you should see something like this in the output:
2014-07-26 15:39:56-0300 [minimal] DEBUG: Crawled (200) <GET http://www.google.com.br/?gfe_rd=cr&ei=_PXTU8f6N4mc8Aas1YDABA> (referer: None)
2014-07-26 15:39:56-0300 [minimal] DEBUG: GETTING URL: http://www.google.com.br/?gfe_rd=cr&ei=_PXTU8f6N4mc8Aas1YDABA
2014-07-26 15:39:57-0300 [minimal] DEBUG: Redirecting (302) to <GET https://br.yahoo.com/?p=us> from <GET https://www.yahoo.com/>
2014-07-26 15:39:58-0300 [minimal] DEBUG: Crawled (200) <GET https://br.yahoo.com/?p=us> (referer: None)
2014-07-26 15:39:58-0300 [minimal] DEBUG: GETTING URL: https://br.yahoo.com/?p=us
To make our code even cleaner, we can take advantage of the default
implementation of start_requests(): if you don't define it, Scrapy will
create requests for a list of URLs in the attribute named start_urls -- the
same kind of thing we're doing above. So, we'll keep the same functionality and
reduce the code, using:
import scrapy
class MinimalSpider(scrapy.Spider):
"""A menor Scrapy-Aranha do mundo!"""
name = 'minimal'
start_urls = [
'http://www.google.com',
'http://www.yahoo.com',
]
def parse(self, response):
self.log('GETTING URL: %s'% response.url)
Like in the parse() method shown above, every callback gets the content of
the HTTP response as an argument (in a
Response
object). So, inside this callback, where we already have the content of the
page, that's where we'll do the information extraction, i.e., the data scraping
itself.

Callbacks, Requests & Items
Functions registered as callbacks for the requests can return an iterable of objects, in which every object can be:
-
an instance of a subclass of scrapy.Item, which you define to contain the data to be collected from the page
-
an object of type scrapy.Request representing yet another request to be made (possibly registering anothercallback)
With this mechanism of requests and callbacks that may generate new requests (with new callbacks), you can program the navigation through a site generating requests for the links to be followed, until getting to the pages that contain the items you're interested. For example, for a spider that needs to extract products from the website of an online store navigating through categories, you could use a structure like the following:
import scrapy
class SkeletonSpider(scrapy.Spider):
name = 'spider-mummy'
start_urls = ['http://www.some-online-webstore.com']
def parse(self, response):
for c in [...]:
url_category = ...
yield scrapy.Request(url_category, self.parse_category_page)
def parse_category_page(self, response):
for p in [...]:
url_product = ...
yield scrapy.Request(url_product, self.parse_product)
def parse_product(self, response):
...
In the above structure, the default callback --parse() method -- handles the
response of the first request to the online store website and generates new
requests for the pages of the categories, registering another callback to
handle them -- the parse_category_page() method. This last method does
something similar, generating the requests for the product pages, this time
registering a callback that extracts the item objects with the product data.
Why do I need to define classes for the items?
Scrapy proposes that you create a few classes that represent the items you intend to extract from the pages. For example, if you want to extract the prices and details of products from an online store, you could use a class like the following:
import scrapy
class Product(scrapy.Item)
description = scrapy.Field()
price = scrapy.Field()
brand = scrapy.Field()
category = scrapy.Field()
As you can see, the item classes are just subclasses from scrapy.Item in which you add the desired fields (instances of the class scrapy.Field). You can then use an instance of this class like if it were a Python dictionary:
>>> p = Product()
>>> p['price'] = 13
>>> print p
{'price':13}
The biggest difference from a traditional dictionary is that an Item by default does not allow you to assign a value to a key that was not declared as a field:
>>> p['silly_walk']=54
...
KeyError:'Product does not support field: silly_walk'
The advantage of defining classes for items is that it allows you to take advantage of other features of the framework that works for these classes. For example, you can use the feed exports mechanism to export the collected items to JSON, CSV, XML, etc. You can also exploit the item pipeline features, that allows you to plug-in other processing on top of the collected items (things like validating the extracted data, removing duplicated items, storing in a database, etc).
Now, let's do some scraping!
To do the scraping itself, i.e., extracting the data from the page, it's nice if you know XPath, a language created for doing queries in XML content which is core to the selectors mechanism of the framework. If you don't know XPath, you can use CSS selectors in Scrapy just as well. We encourage you to learn some XPath nevertheless, because it allows for expressions much more powerful than just CSS (in fact, the CSS functionality in Scrapy works by converting your CSS expressions to XPath expressions). We'll put some links to useful resources about these at the end of the article.
So, you can test the result of XPath or CSS expressions for a page using the Scrapy shell. Run the command:
scrapy shell http://stackoverflow.com
This command makes a request to the informed URL and opens a Python shell (or
IPython, if you have it installed) while making available some objects for you
to explore. The most important object is the variable response, which contains
the response of the HTTP request and corresponds to theresponse argument
received by the callbacks.

>>> response.url
'http://stackoverflow.com'
>>> response.headers
{'Cache-Control':'public, no-cache="Set-Cookie", max-age=49',
'Content-Type':'text/html; charset=utf-8',
'Date':'Sat, 09 Aug 2014 03:47:31 GMT',
'Expires':'Sat, 09 Aug 2014 03:48:20 GMT',
'Last-Modified':'Sat, 09 Aug 2014 03:47:20 GMT',
'Set-Cookie':'prov=5a8741f7-7ee3-4993-b723-72142d48696c; domain=.stackoverflow.com; expires=Fri, 01-Jan-2055 00:00:00 GMT; path=/; HttpOnly',
'Vary':'*',
'X-Frame-Options':'SAMEORIGIN'}
You can use the xpath() and css() methods of the response object to query
the HTML content in the response:
>>> response.xpath('//title') # gets the title via XPath
[<Selector xpath='//title' data=u' '>]
>>> response.css('title')# gets the title via CSS
[<Selector xpath=u'descendant-or-self::title' data=u' '>]
>>> len(response.css('div'))# counts the number of div elements
1345
The result of calling one of these methods is a list object containing selector
objects resulting from the query. This list object has an extract() method which
extracts the HTML content from all the selectors together. The selectors, on
the other hand, besides having their own extract() method to extract their
content, also have xpath() and css() methods that you can use to do new queries
in the scope of each selector.
Take a look at the examples below in the same Scrapy shell, that will help clearing up things a little bit.
Extracts HTML content from <title> element, calling the extract() method
from the selector list (note that the result is a Python list):
>>> response.xpath('//title').extract()
[u'<title>Stack Overflow</title>']
Stores the first selector of the result in a variable and calls the extract()
method on the selector (see how the result now is just a string):
>>> title_sel= response.xpath('//title')[0]
>>> title_sel.extract()
u'<title>Stack Overflow</title>'
Applies the XPath expression text() to get the text content of the selector,
and calls the extract() method from the resulting list:
>>> title_sel.xpath('text()').extract()
[u'Stack Overflow']
Prints the extraction of the first selector resulting of the XPath expression
text() applied to selector in variable title_sel:
>>> print title_sel.xpath('text()')[0].extract()
StackOverflow
Well, when you have a good grip on this way to work with selectors, the simple way to extract an item is just to create an instance of the desired Item class and fill the values obtained using this selectors API.
Here, take a look at the code of a spider using this technique to get the most frequently asked questions ofStackOverflow:
import scrapy
import urlparse
class Question(scrapy.Item):
link = scrapy.Field()
title = scrapy.Field()
excerpt = scrapy.Field()
tags = scrapy.Field()
class StackoverflowTopQuestionsSpider(scrapy.Spider):
name = 'so-top-questions'
def __init__(self, tag=None):
questions_url = 'http://stackoverflow.com/questions'
if tag:
questions_url += '/tagged/%s' % tag
self.start_urls = [questions_url + '?sort=frequent']
def parse(self, response):
build_full_url = lambda link: urlparse.urljoin(response.url, link)
for qsel in response.css("#questions > div"):
it = Question()
it['link'] = build_full_url(
qsel.css('.summary h3 > a').xpath('@href')[0].extract())
it['title'] = qsel.css('.summary h3 > a::text')[0].extract()
it['tags'] = qsel.css('a.post-tag::text').extract()
it['excerpt'] = qsel.css('div.excerpt::text')[0].extract()
yield it
As you can see, the spider defines an Item class named Question, and uses the
Selectors API to iterate through the HTML elements of the questions (obtained
with the CSS selector #questions > div) and generating a Question object for
each one of these elements, filling all the fields (link, title, tags and
question excerpt).
There are two interesting things worth noticing in the extraction done in the
parse() callback: the first one is that we use a pseudo-selector ::text to
get the text content of the elements, avoiding the HTML tags. The second is how
we use the function
urlparse.urljoin() to
combine the URL of the request with the content of thehref attribute, making
sure that the result of this will be a correct absolute URL.
Put this code in a file named top_asked_so_questions.py and run it using the
command:
scrapy runspider top_asked_so_questions.py -o questions.json
If everything went well, Scrapy will show in the screen the scraped items and also write a file namedquestions.json containing them. At the end of the output, you should see some stats, including the item scraped count:
2014-08-02 14:27:37-0300 [so-top-questions] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 242,
'downloader/request_count': 1,
...
'item_scraped_count': 50,
'log_count/DEBUG': 53,
'log_count/INFO': 8,
...
'start_time': datetime.datetime(2014, 8, 2, 17, 27, 36, 912002)}
2014-08-02 14:27:37-0300 [so-top-questions] INFO: Spider closed (finished)
Note: if you run this twice in a row, you need to remove the output file
questions.jsonfile before each run. This is because Scrapy by default appends to a file instead of overwriting it, which ends up making the JSON file unusable. This is done for historical reasons, it made sense for spiders which used the JSON Lines format (the previous default), and may change in the future.

Arachnoid arguments
You may have noticed that the class for this spider has a constructor
accepting an optional argument called tag.
We can specify a value for this argument for the spider to get the
frequently asked questions with the python tag, using the -a
option:
scrapy runspider top_asked_so_questions.py -o python-questions.json -a tag=python
Using this little trick you can write generic spiders, so that you just pass some parameters and get a different result. For example, you may write one spider for several sites that have the same HTML structure, making the URL of the site a parameter. Or, a spider for a blog in which the parameters define a time range of the posts and comments to extract.
Putting it all together
In the previous sections, you saw how to do web crawling with Scrapy, navigating through the pages of a site using the mechanism of requests and callbacks. You also saw how to use the Selector API to extract the content of a page into items and execute the spider using the commandscrapy runspider.
Now, we shall put it all together in a spider that solves the problem we presented in the introduction: let's scrape the latest "big questions" articles from mentalfloss.com, offering an option to inform the category (Origins, The Body, Fact Check, etc). This way, if you just run the spider, it should scrape all the articles in the blog; if you pass in a category, it should scrape only the articles of that subject.
Note: Before writing a spider, it's useful to explore a little bit the pages of the site using the browser's inspection capabilities and the scrapy shell, so that you can see how the site is structured and you can also try a few CSS or XPath expressions in the shell. There are also some browser extensions that allow you to test XPath expressions directly in a page: XPath Helper for Chrome and XPath Checker for Firefox. Discovering the best way to extract the content of a site using XPath or CSS is more of an art than a science, therefore we won't try to explain much here, but it's worthy telling you that you learn a lot after a little experience.
Have a look at the final code of the spider:
import scrapy
import urlparse
class Article(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
link = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
class MentalFlossArticles(scrapy.Spider):
name = 'mentalfloss-articles'
def __init__(self, category=None):
articles_url = 'http://mentalfloss.com/big-questions'
if category:
articles_url += '/' + category
self.start_urls = [articles_url]
def parse(self, response):
"""Gets the page with the article list,
find the article links and generates
requests for each article page
"""
article_links = response.xpath(
"//header/hgroup/h1/a/@href"
).extract()
for link in article_links:
article_url = urlparse.urljoin(
response.url, link)
yield scrapy.Request(article_url,
self.extract_article)
def extract_article(self, response):
"""Gets the article page and extract
an item with the article data
"""
article = Article()
css = lambda s: response.css(s).extract()
article['link'] = response.url
article['title'] = css("h1.title > span::text")[0]
article['date'] = css('.date-display-single::text')[0]
article['content'] = " ".join(
css('#content-content p::text'))
article['author'] = css(
"div.field-name-field-enhanced-authors"
" a::text")[0]
yield article
Just like before, you can run the spider with:
scrapy runspider mentalfloss.py -o articles-all.json
And to get the articles from each section, you can use commands like:
scrapy runspider mentalfloss.py -o articles-origins.json -a category=origins
or:
scrapy runspider mentalfloss.py -o articles-fact-check.json -a category=fact-check
The code for this spider has a very similar structure to the previous one, with its argument handling and everything.
The main difference is that in this one, the first callback (the parse() method)
generates other requests for the article pages, which are handled by the second
callback: the extract_article() method, which scrapes the article data.
The content extraction also does a little bit more work. We created a css()
helper function to abbreviate calling response.css(<selector>).extract() and
used that to get the result of our selectors to fill the Article item. Note
also how we take advantage of Python's feature of concatenating literal
strings
on the CSS selector for the author field, to break it in two lines.
Final words
If you made until here, congratulations! Here is a trophy for you:

Now that you have learned to write Scrapy spiders and therefore are enabled to download the whole Internet to your home PC, try not to get banned by the website hosts laying around! :)
Visit the official documentation for Scrapy, there is a lot of good stuff there, like the tutorial teaching you how to create complete Scrapy projects, frequently asked questions, tips for doing huge crawls, how to debug a spider, tips on how to avoid being banned and a lot more.
UPDATED: removed -t json from commands, unnecessary since Scrapy 0.24 (thanks, Mikhail!)
UPDATED: added note about Scrapy default behavior of appending to output file (thanks again, Mikhail!)